Alucinação não é bug de ajuste, é arquitetura

Série "IA especializada em telefonia BR", post 3 de 6
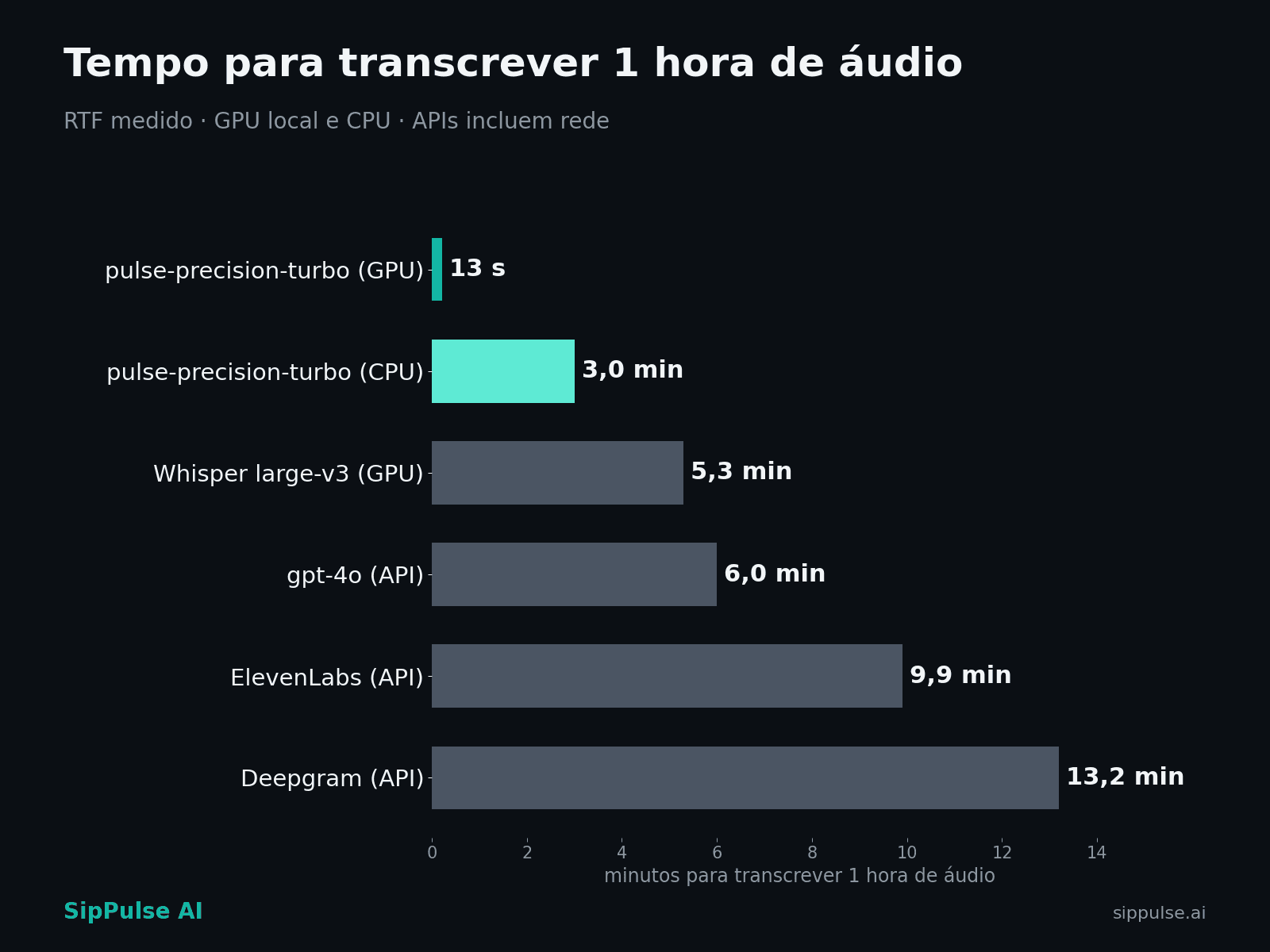
A falha mais grave de um modelo de transcrição não é errar uma palavra. É inventar texto que nunca foi dito.
Um modelo autoregressivo (Whisper, gpt-4o) gera a transcrição continuando o texto anterior, token a token, como um LLM. Em áudio curto, ruidoso ou com silêncio, ele "continua escrevendo": produz frases plausíveis e confiantes com base no que já escreveu, às vezes no idioma errado. Nós medimos isso diretamente nos 261 trechos de telefonia. O gpt-4o-transcribe produziu saída em idioma não-português em 7% dos casos (contra ~0-1% do pulse-precision-turbo) e teve WER acima de 50% em 2 de cada 3 trechos.
Exemplos reais, do mesmo áudio, ambos com language=pt:
REF (humano): Quem gostaria? Ah, tá, só um minuto. Eduardo.
gpt-4o: King of the...
turbo: É o Eduardo. Quem é? Ah, tá. Só um minutinho. Eduardo.
REF (humano): Deixa eu ver aqui hoje não, amanhã também não. Pode ser na sexta?
gpt-4o: Situația nu, măi, am cambei nu. (romeno)
turbo: Deixa eu ver aqui hoje não, amanhã também não.
REF (humano): Milena. Permaneça na linha.
gpt-4o: Good morning, Lisa Malina.
turbo: Milena, permaneça na linha.
Antes de seguir, a leitura honesta dos próprios exemplos: o turbo também erra. No primeiro trecho, trocou "minuto" por "minutinho" e acrescentou um "Quem é?" que não está na referência; no segundo, perdeu o "Pode ser na sexta?" do final. Erro de reconhecimento existe, está medido e publicado. A diferença é de classe: errar ou perder uma palavra é ruído auditável; inventar um parágrafo em outro idioma é um registro falso. E note quem está inventando: o gpt-4o-transcribe é a referência de qualidade dos rankings públicos de áudio limpo.
Isso não é cereja escolhida a dedo. É o comportamento padrão do decodificador autoregressivo diante de áudio de telefonia. O estudo acadêmico "Careless Whisper" (Koenecke et al., ACM FAccT 2024) quantificou o problema: ~1% das transcrições do Whisper continham frases inteiramente inventadas, e 38% dessas traziam conteúdo nocivo. E as alucinações aumentam com a duração dos silêncios, exatamente o que sobra numa ligação: espera, agente digitando, dead air.
Por que o pulse-precision-turbo não faz isso
A diferença é arquitetural. O turbo é um transdutor: avança quadro a quadro do áudio e, em cada quadro, emite um token ou um símbolo "branco", ou seja, nada. No silêncio, a saída natural é uma sequência de brancos. Nenhum texto. Não existe um decodificador gerando parágrafos livremente a partir do texto anterior; a classe mais perigosa de alucinação, inventar conteúdo coerente no silêncio, é eliminada por construção.
Sendo preciso, porque precisão é o assunto: o que a arquitetura elimina é essa classe, não o erro em geral. Erros de reconhecimento continuam existindo (o ~0-1% de saída em idioma errado vem daí) e estão medidos. E a troca tem um custo: transdutores são mais secos em pontuação e formatação do que um decodificador que "escreve bonito". Para telefonia, essa troca vale a pena todas as vezes.
Isso importa mais do que parece na operação. Uma transcrição inventada dentro de um resumo de atendimento vira um registro falso. Numa esteira de cobrança, vira uma promessa de pagamento que o devedor nunca fez. Num processo de compliance, vira evidência contaminada. O custo de uma alucinação não se mede em centavos por minuto.
Precisão a gente compara em tabela, e esse foi o post anterior. Alucinação se resolve na arquitetura. E arquitetura não se conserta com prompt.
Série "IA especializada em telefonia BR", post 3 de 6
A falha mais grave de um modelo de transcrição não é errar uma palavra. É inventar texto que nunca foi dito.
Um modelo autoregressivo (Whisper, gpt-4o) gera a transcrição continuando o texto anterior, token a token, como um LLM. Em áudio curto, ruidoso ou com silêncio, ele "continua escrevendo": produz frases plausíveis e confiantes com base no que já escreveu, às vezes no idioma errado. Nós medimos isso diretamente nos 261 trechos de telefonia. O gpt-4o-transcribe produziu saída em idioma não-português em 7% dos casos (contra ~0-1% do pulse-precision-turbo) e teve WER acima de 50% em 2 de cada 3 trechos.
Exemplos reais, do mesmo áudio, ambos com language=pt:
REF (humano): Quem gostaria? Ah, tá, só um minuto. Eduardo.
gpt-4o: King of the...
turbo: É o Eduardo. Quem é? Ah, tá. Só um minutinho. Eduardo.
REF (humano): Deixa eu ver aqui hoje não, amanhã também não. Pode ser na sexta?
gpt-4o: Situația nu, măi, am cambei nu. (romeno)
turbo: Deixa eu ver aqui hoje não, amanhã também não.
REF (humano): Milena. Permaneça na linha.
gpt-4o: Good morning, Lisa Malina.
turbo: Milena, permaneça na linha.
Antes de seguir, a leitura honesta dos próprios exemplos: o turbo também erra. No primeiro trecho, trocou "minuto" por "minutinho" e acrescentou um "Quem é?" que não está na referência; no segundo, perdeu o "Pode ser na sexta?" do final. Erro de reconhecimento existe, está medido e publicado. A diferença é de classe: errar ou perder uma palavra é ruído auditável; inventar um parágrafo em outro idioma é um registro falso. E note quem está inventando: o gpt-4o-transcribe é a referência de qualidade dos rankings públicos de áudio limpo.
Isso não é cereja escolhida a dedo. É o comportamento padrão do decodificador autoregressivo diante de áudio de telefonia. O estudo acadêmico "Careless Whisper" (Koenecke et al., ACM FAccT 2024) quantificou o problema: ~1% das transcrições do Whisper continham frases inteiramente inventadas, e 38% dessas traziam conteúdo nocivo. E as alucinações aumentam com a duração dos silêncios, exatamente o que sobra numa ligação: espera, agente digitando, dead air.
Por que o pulse-precision-turbo não faz isso
A diferença é arquitetural. O turbo é um transdutor: avança quadro a quadro do áudio e, em cada quadro, emite um token ou um símbolo "branco", ou seja, nada. No silêncio, a saída natural é uma sequência de brancos. Nenhum texto. Não existe um decodificador gerando parágrafos livremente a partir do texto anterior; a classe mais perigosa de alucinação, inventar conteúdo coerente no silêncio, é eliminada por construção.
Sendo preciso, porque precisão é o assunto: o que a arquitetura elimina é essa classe, não o erro em geral. Erros de reconhecimento continuam existindo (o ~0-1% de saída em idioma errado vem daí) e estão medidos. E a troca tem um custo: transdutores são mais secos em pontuação e formatação do que um decodificador que "escreve bonito". Para telefonia, essa troca vale a pena todas as vezes.
Isso importa mais do que parece na operação. Uma transcrição inventada dentro de um resumo de atendimento vira um registro falso. Numa esteira de cobrança, vira uma promessa de pagamento que o devedor nunca fez. Num processo de compliance, vira evidência contaminada. O custo de uma alucinação não se mede em centavos por minuto.
Precisão a gente compara em tabela, e esse foi o post anterior. Alucinação se resolve na arquitetura. E arquitetura não se conserta com prompt.
Artigos Relacionados

Por que treinamos nossos próprios modelos para a telefonia brasileira

O benchmark que importa: 261 chamadas reais revisadas por humanos