O benchmark que importa: 261 chamadas reais revisadas por humanos

Série "IA especializada em telefonia BR", post 2 de 6
A maioria dos rankings públicos de transcrição mede WER em corpora de áudio quase perfeito: palestras, audiobooks, leitura em estúdio. Nesses conjuntos, todos os grandes modelos empatam dentro de ~1 ponto. O problema é que isso não diz nada sobre uma ligação de call center.
Então medimos no áudio que importa. Montamos um conjunto privado de 261 trechos de chamadas telefônicas reais (8 kHz, codecs de telefonia, ruído, sotaques), com transcrição de referência revisada por humanos trecho a trecho. Dados privados: nenhum provedor os viu em treinamento. Somamos dois corpora públicos como controle: o CORAA NURC-SP (500 trechos de fala espontânea brasileira) e o TEDx pt-BR (500 trechos de fala preparada). Não usamos o FLEURS, que é português europeu, irrelevante para a telefonia brasileira.
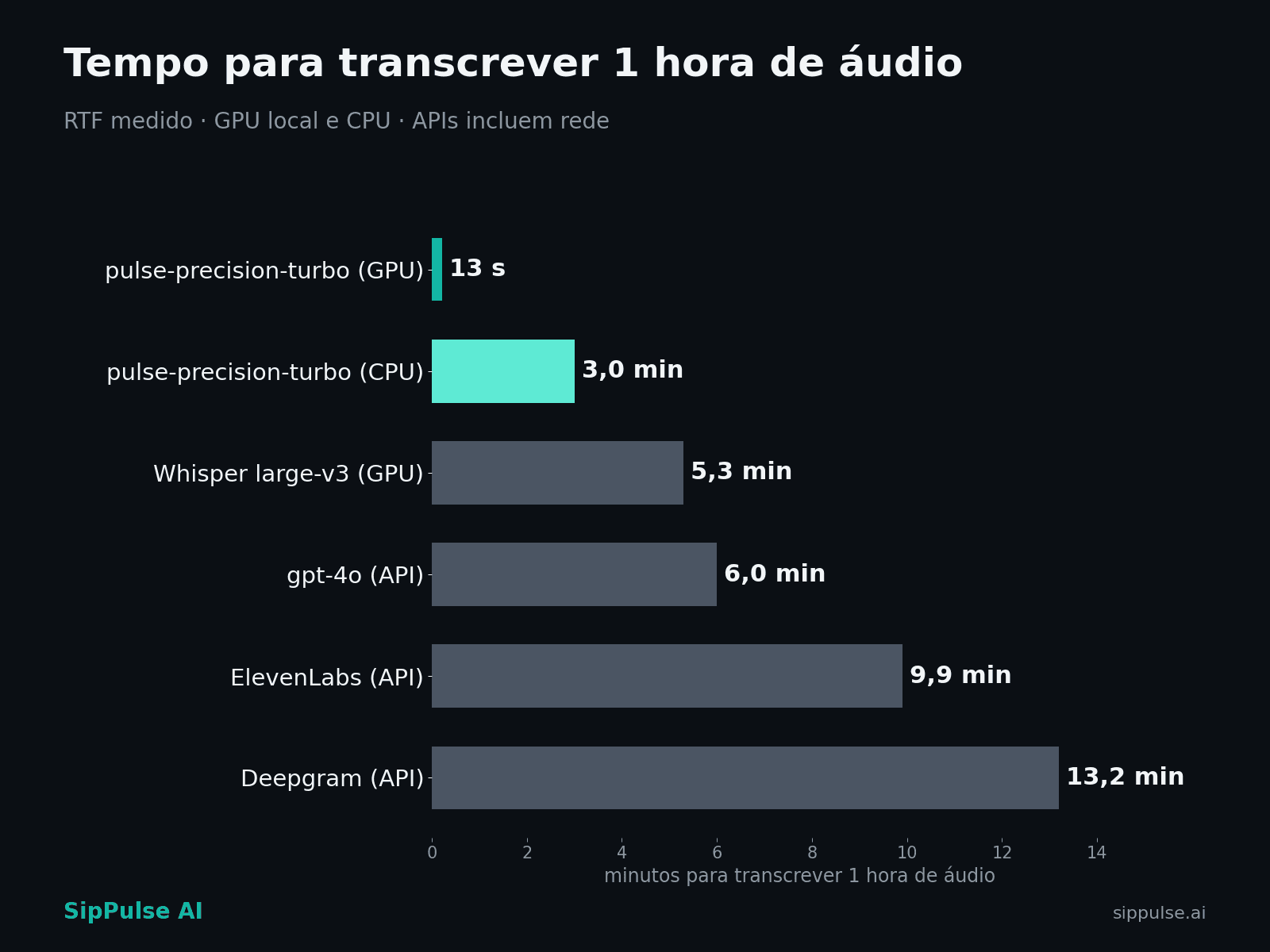
A métrica foi aplicada igualmente a todos: WER com normalização para o português (caixa, pontuação e números por extenso equalizados). Todas as APIs de nuvem foram chamadas com language=pt e formatação inteligente habilitada, o cenário mais favorável a elas. Streaming foi medido como streaming: áudio em ritmo de tempo real nos WebSockets oficiais de cada provedor, incluindo ida e volta de rede.
Os resultados
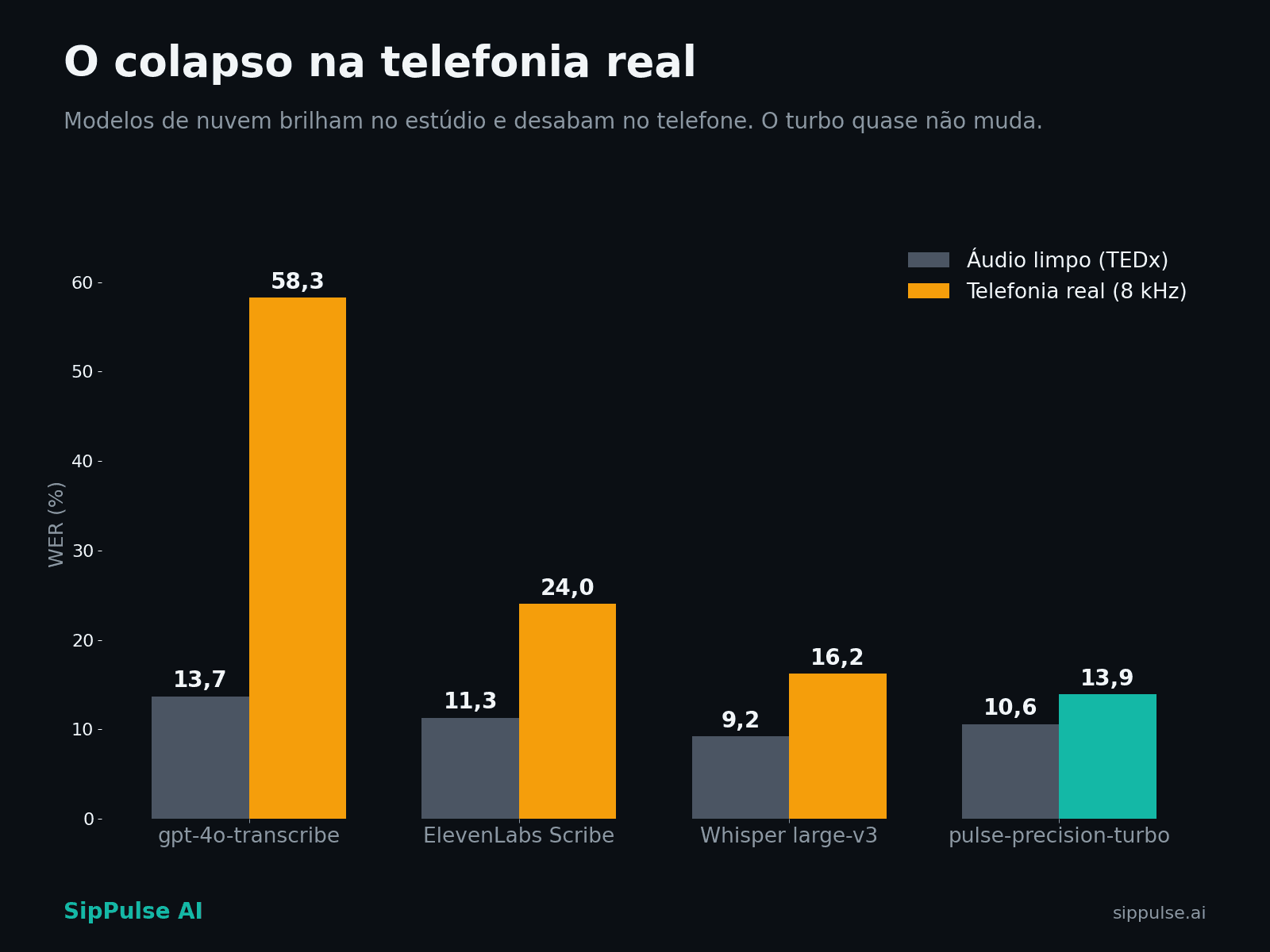
Em batch, no conjunto de telefonia:
| Modelo | Telefonia | CORAA | TEDx | Média |
|---|---|---|---|---|
| pulse-precision-turbo | 13,9% | 13,1% | 10,6% | 12,5% |
| OpenAI Whisper large-v3 | 16,2% | 13,3% | 9,2% | 12,9% |
| AssemblyAI Universal | 15,9% | 14,4% | 10,9% | 13,7% |
| Deepgram Nova-3 | 19,0% | 15,2% | 13,8% | 16,0% |
| ElevenLabs Scribe | 24,0% | 17,0% | 11,3% | 17,4% |
| OpenAI gpt-4o-transcribe | 58,3% | 30,3% | 13,7% | 34,1% |
Em streaming, a condição em que um voicebot de fato opera, quem entra em campo é o pulse-streaming-agent, o modelo da linha específico para escuta ao vivo, que equipa os nossos agentes de voz. Ele fez 19,7% de WER com 157 ms de latência até a primeira palavra, contra 21,3% e 299 ms do Deepgram Nova-3 e 26,0% e 1.153 ms do AssemblyAI (que ainda deixou 10 dos 261 trechos sem nenhum retorno).
A leitura honesta
Repare: o Whisper vence no TEDx (9,2% contra os nossos 10,6%). Não vamos esconder isso. É o dado mais informativo da tabela. TEDx é fala preparada de palestra, quase certamente presente no treino dos modelos de nuvem. É exatamente o tipo de áudio em que eles são imbatíveis, e que não se parece em nada com uma ligação.
Nos dois benchmarks de português do Brasil que importam, a telefonia real e o CORAA, o pulse-precision-turbo vence todos os concorrentes. E no áudio que nenhum modelo viu antes, a vantagem vai de 14% sobre o Whisper a mais de 4× sobre o gpt-4o-transcribe.
O gpt-4o-transcribe merece um parágrafo próprio: é a referência de qualidade dos rankings públicos de áudio limpo (13,7% no TEDx) e desaba para 58,3% na telefonia, mais de 4× pior. O ElevenLabs dobra (11,3% → 24,0%). O turbo quase não muda: 10,6% → 13,9%. É a diferença entre um modelo generalista e um especialista no domínio.
Antes que alguém levante a objeção: sim, nenhum desses modelos foi feito para telefonia 8 kHz. Esse é exatamente o ponto. O áudio do seu call center não se parece com o áudio dos rankings, e um modelo escolhido pelo ranking se comporta ao telefone de um jeito que o ranking não prevê.
Resultados auditáveis: as transcrições completas, com as versões, datas e configurações de cada API testada, acompanham o relatório e estão disponíveis para quem quiser conferir. E se você quiser o único benchmark que realmente importa, o seu: mande 30 minutos das suas chamadas e devolvemos em 48 h o comparativo lado a lado com o seu provedor atual, com as transcrições completas para auditar. O envio é feito por canal seguro, com termo de tratamento de dados assinado antes de qualquer áudio, descarte após o teste e nada vira dado de treino. Devolvemos o relatório e não fazemos follow-up: a próxima ação é sua. contato@sippulse.ai
Artigos Relacionados

Por que treinamos nossos próprios modelos para a telefonia brasileira
Alucinação não é bug de ajuste, é arquitetura